
|
I discuss these problems in my book The Mathematics of Oz.
Order from Amazon.com. |
|
|
I discuss these problems in my book The Mathematics of Oz.
Order from Amazon.com. |
Thanks go to the following people who have provided very useful feedback and information for the solutions to my puzzles: David T. Blackston, Dennis Yelle, Balakumar Jothimohan Balasubramaniam, Ilan Mayer, Ed Murphy, Jim Gillogly, Dan Tilque, Bill Ryan, James Van Buskirk, R.E.S., Dennis Gordon, Dharmashankar Subramanian, Richard Heathfield, Al Zimmerman, Risto Lankinen, Seth Breidbart, Darrell Plank, David A. Karr, and others.
 Possible solutions are at the bottom of this page.
Possible solutions are at the bottom of this page.
 Imagine that a creature
from outer space walks you before a pit. In the pit are 10,000 leg bones.
The creature tells you, "I have cracked each bone at random into two pieces
by throwing them against a rock. What's the average ratio of the length
of the long piece to the length of the short piece? If you cannot find
the solution within 2 days, I will add your leg bone to the pit." How did
you solve this? If you were a betting person, what value would you bet
on for this ratio?
Imagine that a creature
from outer space walks you before a pit. In the pit are 10,000 leg bones.
The creature tells you, "I have cracked each bone at random into two pieces
by throwing them against a rock. What's the average ratio of the length
of the long piece to the length of the short piece? If you cannot find
the solution within 2 days, I will add your leg bone to the pit." How did
you solve this? If you were a betting person, what value would you bet
on for this ratio?
 An alien walks up to you and
hands you a glowing sphere about the size of a basketball. He says, "Inside
the sphere is a random collection of two thousand points. Does there exist
a plane having exactly one thousand of these points on each side of the
plane? If so, why?"
An alien walks up to you and
hands you a glowing sphere about the size of a basketball. He says, "Inside
the sphere is a random collection of two thousand points. Does there exist
a plane having exactly one thousand of these points on each side of the
plane? If so, why?"
 An alien comes up to
you and draws a circle of radius R. He then tells you to toss a thin stick
of length R at the circle so that one end of the stick is on the circle's
edge, but the stick's orientation is completely random. What is the probability
that the other end of the stick is inside the circle? How would your answer
change if the thin stick were of length R/2 or 2R. If you do not respond
properly, the alien may toss you into the circle and devour you.
An alien comes up to
you and draws a circle of radius R. He then tells you to toss a thin stick
of length R at the circle so that one end of the stick is on the circle's
edge, but the stick's orientation is completely random. What is the probability
that the other end of the stick is inside the circle? How would your answer
change if the thin stick were of length R/2 or 2R. If you do not respond
properly, the alien may toss you into the circle and devour you.
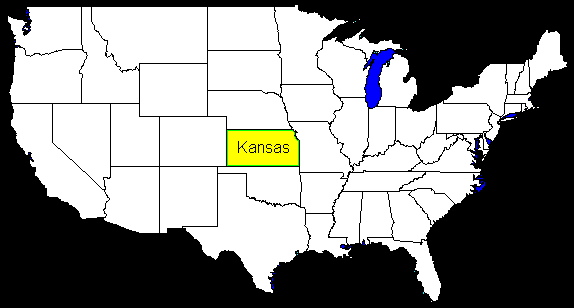
 Consider a globe representing
the Earth. It is spinning. You throw a piece of Silly Putty at the globe
in the shape and size of Kansas. If, during your random toss, your putty
Kansas touches Kansas, you must spend your next vacation in Kansas. What
are the chances of you spending time in Kansas on your first toss? How
does your solution differ for Australia and an Australian-shaped putty?
Consider a globe representing
the Earth. It is spinning. You throw a piece of Silly Putty at the globe
in the shape and size of Kansas. If, during your random toss, your putty
Kansas touches Kansas, you must spend your next vacation in Kansas. What
are the chances of you spending time in Kansas on your first toss? How
does your solution differ for Australia and an Australian-shaped putty?
 An alien takes a leg bone,
N feet long, and shatters the leg into three pieces at random. What is
the probability that these three pieces can be placed together to form
a triangle? For the second part of this problem, the alien hands you the
longest piece of his most recent shatter experiment. If you were a betting
person, what is the most likely ratio of the longest piece of bone to the
shortest piece of bone in each shattered set? How did you solve this?
An alien takes a leg bone,
N feet long, and shatters the leg into three pieces at random. What is
the probability that these three pieces can be placed together to form
a triangle? For the second part of this problem, the alien hands you the
longest piece of his most recent shatter experiment. If you were a betting
person, what is the most likely ratio of the longest piece of bone to the
shortest piece of bone in each shattered set? How did you solve this?
 Two alien ships are
traveling towards one another firing their phasers. Each time a ship fires
it either misses the opponent ship or destroys it totally. Also, each time
a ship fires, it has a 50 percent chance of hitting the opponent ship.
First ship A fires, then ship B, then ship A, alternating until one ship
is destroyed. What are the odds that ship A will survive? How do these
odds chance if each time a ship fires, it has only 10% chance of hitting
the opponent ship? In part two of this question, the ships fire at one
another according to the Fibonacci sequence: 1, 1, 2, 3, 5, 8, 13, 21,
34, 55, 89, 144, 233, 377. In other words, first ship A fires 1 shot, ship
B fires 1 shot, ship A fires 2 shots, and so forth. What are the odds that
ship A will survive for the 50% and 10% scenario? How did you solve this?
Two alien ships are
traveling towards one another firing their phasers. Each time a ship fires
it either misses the opponent ship or destroys it totally. Also, each time
a ship fires, it has a 50 percent chance of hitting the opponent ship.
First ship A fires, then ship B, then ship A, alternating until one ship
is destroyed. What are the odds that ship A will survive? How do these
odds chance if each time a ship fires, it has only 10% chance of hitting
the opponent ship? In part two of this question, the ships fire at one
another according to the Fibonacci sequence: 1, 1, 2, 3, 5, 8, 13, 21,
34, 55, 89, 144, 233, 377. In other words, first ship A fires 1 shot, ship
B fires 1 shot, ship A fires 2 shots, and so forth. What are the odds that
ship A will survive for the 50% and 10% scenario? How did you solve this?
 Imagine ten tombs, A, B, C, D,
E, F, G, H, I, J. A single tunnel connects tomb A to B, B to C,... and
finally I to J. The area of the floor of each tomb corresponds to the Fibonacci
sequence, so that the tomb A has a floor with 1 square mile area, tomb
B has an floor space of 1 square mile, tomb C has a floor space of 2 square
miles, and so forth up to tomb J. Assume that an alien introduces 10,000
people into tomb A, and they randomly wander the tombs. After a long time,
where do you expect to find the most people? (Assume that the humans randomly
move through the tombs. There is no escape from the tombs.)
Imagine a race of aliens
with varying degrees of greenness. Some are very green. Some are pale --
almost white. In a rectangular array of aliens, which will be greener,
the greenest of the palest aliens in each column, or the palest of the
greenest aliens in each row? Can you extend your logic from a rectangular
array to other array shapes or to higher dimensional shapes?
Imagine ten tombs, A, B, C, D,
E, F, G, H, I, J. A single tunnel connects tomb A to B, B to C,... and
finally I to J. The area of the floor of each tomb corresponds to the Fibonacci
sequence, so that the tomb A has a floor with 1 square mile area, tomb
B has an floor space of 1 square mile, tomb C has a floor space of 2 square
miles, and so forth up to tomb J. Assume that an alien introduces 10,000
people into tomb A, and they randomly wander the tombs. After a long time,
where do you expect to find the most people? (Assume that the humans randomly
move through the tombs. There is no escape from the tombs.)
Imagine a race of aliens
with varying degrees of greenness. Some are very green. Some are pale --
almost white. In a rectangular array of aliens, which will be greener,
the greenest of the palest aliens in each column, or the palest of the
greenest aliens in each row? Can you extend your logic from a rectangular
array to other array shapes or to higher dimensional shapes?
 For any positive integer n let f(n)
denote the integer given by the recurrence
For any positive integer n let f(n)
denote the integer given by the recurrence
f(n) = 10 f(n-1) + n
with the initial value f(0) = 0. This means f(1)=1, f(2)=12, f(3)=123, etc. We know from Kevin Brown's work that the square roots of f(n) for odd integers n give a persistent pattern. The result appears to be rational for periods, and then disintegrates into irrationality. For example, for sqrt[f(49)] we get
1111111111111111111111111.1111111111111111111111 0860 555555555555555555555555555555555555555555555 2730541 66666666666666666666666666666666666666666 0296260347 2222222222222222222222222222222222222....What other formulas exist for finding irrational numbers that exhibit seemingly amazing patterns of digits? Please give examples. For example, does the square root of 111111111111111 yield an irrational number with strange repetitions? Does the square root of 121212121212 yield an irrational number with strange repetitions? What other numbers Y can you find such that sqrt (Y) exhibits apparent patterns in the first hundred digits?
 Imagine a yellow brick road stretching
from the East to the West coast of America. Estimate the number of bricks
in such a road. How did you arrive at your estimate? What impressive structures
could you build with this number of bricks? How would these structures
compare in dimensions with structures already on Earth? How tall a structure
could you build with this number of bricks that would be stable and last
for a thousand years?
Imagine a yellow brick road stretching
from the East to the West coast of America. Estimate the number of bricks
in such a road. How did you arrive at your estimate? What impressive structures
could you build with this number of bricks? How would these structures
compare in dimensions with structures already on Earth? How tall a structure
could you build with this number of bricks that would be stable and last
for a thousand years?
One way to attack this
problem is to try to find an "average value" for the ratio of long piece
to short piece. Unfortunatley, it turns out that there is no average value
for the ratio. In order to try to find an average ratio, one may resort
to some simple calculus:
Integral from x=0 to x=.5 of (1-x)/x dx + Integral of x=.5 to x=1 of x/(1-x) dx.
This equals 2 Integral from x=0 to x=.5 (1-x)/x dx or 2[(ln x - x) from 0 to 0.5], but this diverges as x approaches 0. This means there can be no average ratio of bone lengths.
However, what would you do if "forced" to provide an answer to the alien? David T. Blackston suggests that if R is our ratio of bone parts and x is our breakpoint along the bone, then the probablity of obtaining a ratio less than 3 (R<3) is the probability of (.25<x<.75), which equals 1/2.
This means I would choose a ratio of 3 in my wager with the alien.
We obtain the range "(.25<x<.75)" by noting that the ratio R is symmetric about the line (x=1/2). Blackston wanted to find two points y and z symmetric about 1/2 such that their difference was 1/2. This led to y=1/4, z=3/4, and the ratio for these endpoint values is 3.
Click here for Nandor's detailed paper on "The Problem of the Bones."
Darrell Plank: Change "average" to "median" and your answer of 3 is correct.
The notion of "average value" used to examine problem 1 is a generalization of the expected value of a discrete random variable. One can express a continuous distribution as the limit of discrete distributions. In our problem, the average value of the random variable diverges, which means that the average value does not exist. This can be seen a little more intuitively in the following way. Blackston asks us to consider the discrete random variable P that takes on the following values. We choose x uniformly at random from [0, 1].
P = 0 if 1/2 < x <= 1
P = 1 if 1/3 < x <= 1/2
P = 2 if 1/4 < x <= 1/3
...
P = n if 1/(n+2) < x <= 1/(n+1)
...
We note that P is always at most R, the ratio of the larger
piece to the smaller piece. Also, the expected value of P is going to be
1 (1/2 - 1/3) + 2(1/3 - 1/4) + ... = 1/2 + 1/3 + 1/4
+ ...
which diverges.
A lesson in random variables: To best understand how to calculate the expected value of a random variable, consider that the mean of a random variable, also known as its expected value, is the weighted average of all the values that a random variable would assume in the long run. We can compute the expected value by making The expected value of a random variable can be computed by making the variable assume values according to its probability distribution. We next record all the values and calcualte the mean. If we do this again and again the calculated mean of the values will approach some finite quantity. If the mean does not approach a finite quanity, the mean is said to diverge to infinity and the mean of the radnom variable does not exist.
Let's denote the expected value of a random variable Z as A(Z) For a discrete random variable, A(Z) is calculated from
A(Z) = sum over all z [z pz(z)]
As an example, let's consider dice. Out of the 36 possible rolls of the dice, there is only 1 way to get a "2" (by throwing two 1s) and 1 way to get a 12 (by throwing two 6s). The random variable Z has the following probability distribution for (z, pz(z)): (2, 1/36) (3, 2/36,) (4, 3/36), (5, 4/36), (6, 5/36), (7, 6/36), (8, 5/36), (9,4/36), (10, 3/36), (11, 2/36), (12, 1/36).
The random variable Z assumes a value equal to the sum of two dice rolls. Its expected value is calculated as A(Z) = sum from i=2 to 12 of z [z pz(z)]
= 2(1/36) + 3(2/36) + 4(3/36) + 5(4/36) + 6(5/36) + 7(6/36) + 8(5/36) + 9(4/36) + 10(3/36) + 11(2/36) + 12(1/36) = (1/36) (2 + 6 + 12 + 20 + 30 + 42 + 40 + 36 + 30 + 22 + 12) = (252/36) = 7
In the long run, the average value of two dice rolls using regular dice is 7.
Yelle says about the origianl problem: If we ignore the fact that bones tend to be bigger on the ends, which means they are unlikely to break near the ends, then I would bet that the answer is larger than 10. My simulation results indicate that most any number bigger than 10 is possible.
I get similar simulation results, with the arithmetic mean almost always between 10 and 1000. Of course any value in the interval [1,infinity) is *possible* in an idealized model.
If by average ratio the alien meant product((/(r(i),i=1,n)/))**(1.0/n), where r(i) is the ith ratio, then you get something like 1/(2*exp(1)).
For the geometric mean, G_n=(product(r(i), i=1..n))^(1/n), my simulations indicate that as n->oo, G_n -> 4 (or something very close to 4). For n=10^4, it's almost always 4.0 +- 0.1.
Wait, I did the wrong integral here (obviously any answer less than unity is deficient in some respect) and starting from the correct integral I get the geometric mean to be exactly 4, as your simulations suggest. Do your simulations yield about 1/(ln(2)-1/2) for the harmonic mean? It was nice to see that measuring 1% of the ratios got an error of better than 1% for the arithmetic mean in many cases.
Simulations (R.E.S.) suggest that the harmonic mean,
H_n = 1 / arithmetic_mean{ 1/r(i), i=1..n },
converges to half of that result, i.e.,
H_n -> 1/(2*ln(2)-1) = 2.588699... as n approaches infinity.
For n=10^4, it lives mostly in the interval 2.59 +- .04, spending most of its time in 2.59 +- .01.
What is the harmonic mean all about? For the given two quantities, 20 and 30, the number (20 + 30)/2 = 25 is known as their arithmetic mean while 2/(1/20 + 1/30) = 24 is the harmonic mean of the two numbers. Given a sequence of N>0 numbers a1,a2,...,aN, we define an arithmetic mean or average as
If none of the numbers is 0, we also define their harmonic mean by
2.588 might be a good "ratio" to tell the alien and to bet on if the alien really meant the "harmonic mean" by the word "average". (The problem seems harder using the arithmetic mean, but I don't think that's a good reason to think the alien meant harmonic mean.)
The usual average, the arithmetic mean, is the sum of all the values divided by the number of those values. On the other hand, if we calculate the arithmetic mean of of the *reciprocals* of all the values, and then take the reciprocal of the result, we get the "harmonic mean".
Since the possible values we're averaging in this problem fall in the interval [1, oo), taking reciprocals produces values that fall in the interval (0,1]. Consequently (under assumptions about random sampling), as the number of values increases, the arith. mean of their reciprocals will almost surely tend to converge to some precise finite limit, unlike the arith. mean of the original values themselves. Taking the reciprocal of the result then brings it back into the orignal interval [1, oo) as a "typical" value.
This idea can be extended to many kinds of "means" as follows. If the values are {r(i), i=1..n}, introduce an invertible function g(r), and transform the data to {g(r(i)), i=1..n}. Now take the arithmetic average of the transformed values, T = (1/n) sum( g(r(i)), i=1..n ), and then bring T back to the original data-interval as the "mean value" g¬-1 (T), where g¬-1 is the inverse of g. (The "harmonic mean" corresponds to taking g(r) = 1/r, and the "geometric mean" uses g(r) = log(r), etc.)
If it really does indicate arithmetic mean could you change
your simulation so that perhaps the contribution of the 100 smallest fragments
to the mean are evaluated directly and the others are estimated by an integral?
How close do you get to the actual mean by this technique?
Interesting idea! But to find the contribution of the
smaller pieces, we'd need to locate their mates among the longer pieces
(in order to find their length ratios). If we suppose this is possible,
here's a way to apply your idea:
Collect pieces, beginning with the shortest ones, finding the mates to each, and express the length of each smaller piece as a fraction of the length of the whole bone. Keep the pair only if this "normalized length" is less than some number, say a, 0 < a < 1/2 (e.g. a=0.005), and suppose there are m such pairs kept. Using these m pairs, we measure only m of the n ratios r(i). Let the arithmetic mean of these m ratios be A.
Now the arithmetic mean of the ratios for all n pairs is
R = (m/n)*A + ((n-m)/n)*B
where B is the arithmetic mean of the remaining n-m ratios.
f(r) = (2/(1-2a))/(1+r)^2 ( 1 < r < (1-a)/a ).
Since this density lives on a finite interval its variance must be finite, so that (assuming the ratios are statistically independent) B will almost surely converge to the expectation value corresponding to this density, which is
E = ( 2*(a - ln 2 - ln a) - 1 ) / (1 - 2a), 0 < a <1 /2.
Therefore, our estimate of R is
R' = (m/n)*A + ((n-m)/n)*E,
where A and E are as defined above. (Note that m is a random variable in this method.)
As an example, my simulations indicate that if a=0.005, then almost surely |R' - R| < 0.5, and m will be about 100. (This seems like pretty good precision with R very often in the hundreds.) To get better precision, the value a would need to be made larger, resulting also in a larger number m of ratios to measure.
Murphy writes: Integrating (1-x)/x from 0 to 1/2 indicates that the average ratio approaches infinity as the number of bones approaches infinity. Some empirical trials indicate that the average ratio is usually about 20 to 1. To get the exact average for this set of 20,000 half-bones, arrange them in order of length, then match longest to shortest; this works perfectly if all bones were the same length before being broken, and is a good heuristic if they were roughly the same length.
Van Buskirk: A couple of thoughts on this: does average always imply arithmetic mean in this forum? If by average ratio the alien meant product((/(r(i),i=1,n)/))**(1.0/n), where r(i) is the ith ratio, then you get something like 1/(2*exp(1)). If it really does indicate arithmetic mean could you change your simulation so that perhaps the contribution of the 100 smallest fragments to the mean are evaluated directly and the others are estimated by an integral? How close do you get to the actual mean by this technique?
Note that that you can't pick up any two bone fragments, divide them, and move on, hoping that the average ratio would be the same as if you had picked up the bones in some other order. For example, consider five bones as follows:
Length 8, frags 3,5 Length 8, frags 4,4 Length 9, frags 3,6 Length 9, frags 4,5 Length 11, frags 4,7The mean ratio for these five bones and 10 fragments is about 1.53.
However, if we shuffle and match them as follows: (3,4) (3,5) (4,5) (4,6), (4,7) we get a mean ratio of about 1.50.
This means the value isn't invariant on how the bones are matched; I imagine you could have seen that without doing the experiment.
If we try the heuristic one person suggested, we'd match the longest with the shortest, and so on (feasible within two days). In this case it's (3,7) (3,6) (4,5) (4,5) (4,4), for a mean ratio of about 1.57.
This is what I mean by saying it's not invariant with respect to how you match the fragments, so that in order to get the actual ratio you need to get the correct fragments together.
This means to me you need to come up with an algorithm to find the correct matches for all 20,000 fragments.
However, the problem really is a theoretical one involving zillions of cut line segments for which you have all information about the lines and breaks in lines.) How would your answer change if the creature asked for the expected ratio or an estimate of the ratio? I ran a few approximations (not yet simulations), but the variance must be very high, since a very short piece will wrench the ratio. I think the ratio is unbounded as the number of fragments approaches infinity, but I suppose finding the ratio at 20,000 fragments is a well-formed question. Perhaps I would measure the fragments and run a bunch of simulations making assumptions about the distribution of leg-bone lengths in the population of victims of this monster. The shortest and longest fragments would give us bounds of some sort. Inspecting them to see whether the bones broke near the joints would also be helpful: if we can establish that there can be no really short fragments, I conjecture we would be spared the unbounded ratios.
Murphy says, Assume that any point is equally likely to be a breakpoint. Draw a graph with the following rules:
X = ratio of (length of short part) to (length of entire
bone)
Y = ratio of (length of long part) to (length of short
part)
Our rule for X means that a range of 0 to 0.5 is appropriate, and also means that the ratio of (length of long part) to (length of entire bone) is (1-X). Hence Y = (1-X) / X = (1/X) - 1 and the integral is [(ln X) - X].
Murphy BASIC code for simulation ... Line 40 should give P a random value between zero and one.
10 N = 10000 20 T = 0 30 FOR C = 1 TO N 40 P = RND 50 IF P >= 0.5 THEN L = P ELSE L = 1 - P 60 S = 1 - L 70 T = T + (L / S) 80 NEXT C 90 PRINT T / NIf I were a betting man, I wouldn't bet at all. I might bet one-to-one odds that the ratio is somewhere between 15-to-1 and 25-to-1, though.
The average ratio is increased by a breakpoint near the end more than it is decreased by a breakpoint equally near the middle. Therefore, the more bones we examine, the higher the average ratio. Consider the simple case of one bone: there is a 10% chance of the average ratio being more than 10-to-1. For two bones, there is a better than 20% chance of the average ratio being more than 10-to-1. And so on.
As the number of bones approaches infinity, the average ratio approaches infinity. This is what the integration measures.
Nandor's response to the above follows:
1.Your solution: you can only use that integral if there are an infinite number of bones. If there are a finite number of bones, the average is not undefined. In fact, to find it all we would have to do is add up all the ratios and divide by the number of bones. You can use the integral if both of the following are true: a) there are an infinite number of bones and b) you have infinitely precise measurements. Even then, since the breaks are random, we are not guaranteed that each differential function value will be sampled an equal number of times, so I'm not sure the integral applies. To use the integral in it's entirety, I think you need to multiply the integrand by a Green's Function composed of an infinite sum of Dirac Delta Functions, each with an argument of (x - rnd), where rnd is an random real number between 0.5 and 1.0, not inclusive. In other words, I don't think you can realistically use the calculus and hope for an answer.
2. David T would guess 3 since half the time the ratio will be larger than this and half the time it will be less than this. Guessing 3 would be fine if the ratios were equal on either side of 3, but the numbers are so large on the rhs of 3 that we can't use 3 as a reasonable average. The same goes for Blackston's explanation.
3. Darrell Plank's reasoning is correct, but he does not offer a solution. The same goes for Yelle.
4. R.E.S. wants to do half the problem discretely and half of it using the calculus. However, as shown above, this won't work.
5. Murphy comes close to the correct answer (he says it's about 20 and the correct answer is about 18.0), but he does not explain at all how he gets it!
6. Van Buskirk gets stuck worrying about how to sort the bones to match them up, but that isn't any part of the question. The way the question is phrased, it is already assumed that each ratio is known or can be known. The problem is not that the bones are a puzzle to be put together, but rather that there is a known number out there, the average ratio of each bone, and we must find it. But if the Bone Man knows what the average ratio is, he must have known what each ratio was to begin with.
7. Murphy later supplies us with a BASIC code for finding an average ratio of a given pile of bones, and he says that we should guess between 15 and 25. Indeed, that is where almost all of the probability lies. So kudos to Murphy. If he had run his program a million times and plotted the results, I assume he would have come up with the same number, 18.0, that I did. He does not give a convincing argument as to why the number resides there, however.
So far, to the best of my knowledge, I'm the only one that has presented a solution that everyone essentially agrees with, although admittedly most people have not worked through all of the math and have just looked at some of my histograms. Of course, probably no one else "wasted" a couple weeks of their life working on this one problem, either! Thanks for the interesting puzzle!
Yes, you can find such a plane.
It exists. Consider all the planes determined by triplets of points in
the omega sphere. Pick a new line beloning to none of these planes and
outside of the sphere. Consider a plane through this new line and to the
left of the 2000 points. Imagine rotating this plane about the new line
and towards the right of the points. You can rotate this plane until it
has pass through exactly 1000 points, at which location it becomes a plane
dividing the sphere into 1000 points on each side of the plane.
Here is another way to look at this problem. There are a finite number of points, therefore there are a finite number of lines containing two of the points. This means there must be a plane such that no plane parallel to this plane contains any of these lines. This means that if we start with a plane parallel to this plane and outside of the glowing sphere and then move the plane through the sphere we will encounter the points one by one. (We can't encounter two of the points simultaneously since the plane cannot contain any of the line segments.) Hence there will be a small interval between the 1000th and the 1001th points, and any plane in this interval will satisfy the requirements.
Yelle says: Yes. Consider the horizontal plane above the sphere: zero points are above it. Slowly lower the plane. Slowly the number of points above the plane increase. Eventually the number will either become exactly 1000, or slightly more. The probability of slightly more is zero, but if this case happens, just start again with a plane that is slightly tilted.
Murphy says, Yes. Consider the finite set S of all planes containing two or more of the points. Choose a plane P not parallel to any member of S, a line L perpendicular to P, and establish Cartesian coordinates with L as the X-axis. For any given X-value, the set P' of all points with that X-value is a plane parallel to P, thus is not in S, thus contains at most one of the points. So all points have different X-values. The plane P* of all points with an X-value equal to the median of the points' X-values will have exactly one thousand of the points on each side.
Darrell Plank: This is a pretty common procedure in computational geometry and a lot of "divide and conquer" algorithms use this. Also, the so called "sweep plane" algorithms which may or may not insist that the points be in "general position (i.e., no three in a line, no four in a plane).
There are probably many ways to attack this problem. Can you come up with a simpler solution? One way to answer this question is to start by answering the related question "How many times does 1 appear as the units digit?" By symmetry this will be the same as the number of times each of 2, 3, 4, 5 and 6 appear as the units digit. Let C(m,n)=m!/(n!(m-n)!) be the m,n th binomial coefficient. The total number of numbers in the sum is C(12,2)C(10,2)C(8,2)C(6,2)C(4,2)C(2,2). (This follows from simple combinatorics.) Let this number be X. The number of times 1 appears as the units digits would be (X/6). The total sum of the units digits would then be (X/6)(1+2+3+4+5+6). The total sum would then be (X/6)(1+2+3+4+5+6)(111111111111). Blackson didn't have a calculator handy so did not calculate the sum.
The sum is: 111111111111 times 26195400 which is about 2.9106E18.
Another way to attack this is to consider that the sum of the digits in each number is 1+1+2+2+3+3+4+4+5+5+6+6 = 42. Next, consider how many ways there are to create this sum.
Seth Breidbart: Nobody seems to have noticed that a six-fingered alien would most likely not count in base 10.
How many numbers there are is a simple calculation. Each digit appears equally often in each position, so the average digit is 3.5. The final result is (3.5 * #numbers * 111111111111[alien]), where the string of 12 1's is interpreted as a number in the alien's base.
To interpret what I just wrote... the number of sequences of digits 1-6, each used twice (so each sequence is of length 12) is 12! / (2**6). (Proof: The number of sequences of digits 1-B, each used once, is 12!. Now subtract 6 from each digit >6, and notice that each sequence appears 2**6 times.)
So the result is
3.5 * (12! / (2**6)) * 111111111111
More explanation: Write all the numbers in a column. Now, swapping two digits that are in the same position in different numbers won't affect the sum, so swap them around putting all the 1's at the top, then the 2's, etc. You end up with (12! / (2**6)) / 6 numbers that are all 1's, an equal number that are 2's, etc. Thus, the sum is ((12! / (2**6)) / 6) * (1+2+3+4+5+6) * 111111111111.
The (1+2+3+4+5+6)/6 term (which we get from a little rearranging) is 3.5.
I still think this problem is mainly worth considering for the trick that a 6-fingered alien isn't likely to use base 10; otherwise, it's more like a homework exercise.
Darrell Plank: I thought about the base 6 aspect, but the fact that the alien asks you to use digits 1-6 kinda made that a tough fit in my mind. I just figured that the number of times a digit is in a column is the multinomial 11!/(1! 2! 2! 2! 2!). multiply by 21*111111111111 to get the same answer everyone else did.
n n mod 23232 n mod 232 2323 2323 3 25555 2323 35 48787 2323 67 72019 2323 99 95251 2323 131 118483 2323 163 141715 2323 195 164947 2323 227 188179 2323 27 211411 2323 59 234643 2323 91 257875 2323 123 281107 2323 155 304339 2323 187 327571 2323 219 350803 2323 19 374035 2323 51 397267 2323 83 420499 2323 115 443731 2323 147 466963 2323 179 490195 2323 211 513427 2323 11 536659 2323 43 559891 2323 75 583123 2323 107 606355 2323 139 629587 2323 171 652819 2323 203 676051 2323 3 699283 2323 35 722515 2323 67 745747 2323 99 768979 2323 131Notice that the third column repeats starting at the second 3, and that no 23 appears in the third column.
Gillogly says, If 23, 232, 2323 and 23232 were relatively
prime the Chinese Remainder Theorem would guarantee a minimal solution
that satisfies all of these. However, they aren't. If we use just the last
two (N mod 23232 = 2323 and N mod 2323 = 232, which are relatively prime),
we get the minimal equation for those two:
N mod 53967936 = 2697235
If we start with 2697235 and check the result mod 232,
we get a residue of 3. Adding 53967936 to it, to satisfy our equation for
the last two, we get 99 for the next residue mod 232. Continuing this process,
we get: 3 99 195 59 155 19 115 211 75 171 35 131 227 91 187 51 147 11 107
203 67 163 27 123 219 83 179 43 139 3 99...
That is, it starts looping after 30 iterations without having reached 23, and there is thus no solution to all four of the requirements.
I think we can count on alien control of 23 nations in the near future. Looks like the U.S. is already scheduled for its dose in January.
An easier way to show there is no solution is to observe that if N = 23 mod 232, N = 7 mod 8, but if N = 2323 mod 23232, N = 3 mod 8.
If the numbers that you divide by are all prime, there will be an answer. The problem is that a number of the form xyxy will always be divisible by 101 and xy, so it will not be prime.
Although 2323... does not work, what other repetitive digits will work to yield an interesting solution?
The second problem requires finding three consecutive cubes. Clearly, -1, 0, and 1 must be the cubes leading to the solution -101.
Balasubramaniam says no integer solution exists. reason: let the unknown number to be added be 'a' and the squares be k,q,z;
100+a=k*k 200+a=q*q 300+a=z*zeq(2)-eq(1) gives 100=(q-k)*(q+k)
No solution is possible with rational numbers. What we would need is an arithmetic sequence of squares differing by 100.
Lets look at rational square sequences. I believe that they must be of the form [n(a^2-b^2-2ab)]^2, [n(a^2+b^2)]^2, and [n(a^2-b^2+2ab)]^2 for any integers a and b and any rational n (including fractions). [See Note 1].The difference between these squares is n^2*4ab(a^2-b^2).
Setting this equal to 100 and doing some basic math yields sqrt[ab(a+b)(a-b)]=5/n where 5/n is rational and a and b are integers. If there are solutions to this equation, they can be expressed in lowest terms where a and b are mutually prime. If so, then neither a nor b can divide (a+b) or (a-b), meaning that no rational square root is possible.
[Note 1. Take any Pythagorean triangle. take the difference between the legs , the hypotenuse, and the sum of the legs. Multiply each by n. The squares form an arithmetic sequence.]
*****
(b) What number added separately to 100, 101 > and 102,
will make the three results three different cube numbers?
*****
The number -101 will do.
Van Buskirk: Perhaps I haven't read all the responses carefully enough, but this problem seems simpler to analyze if you consider that all three sums must be quadratic residues mod 3. Problem 4 is also easy if you think about it mod 8.
We find that 100, 200 and 300 do not yield a solution. Can you find any other triplets > 10 that do yield a solution? Yelle says, there are lots of them, here are some:
1 25 49 4 100 196 49 169 289 9 225 441 49 289 529 16 400 784 289 625 961 196 676 1156 25 625 1225 1 841 1681 36 900 1764 196 1156 2116 529 1369 2209 49 1225 2401 961 1681 2401 441 1521 2601 64 1600 3136 1156 2500 3844 81 2025 3969 784 2704 4624 441 2601 4761 100 2500 4900 2401 3721 5041 289 2809 5329 121 3025 5929 2209 4225 6241
Gathering our simplifying assumptions, we need y to be a cube, and 5y to be a square. We choose y=5^3, and this leads to a solution (625, 125, -125). The sum of the cubes is 3125^2, and the sum of the squares is (3*25)^3.
Other ideas:
-2, 0, 2 2 2 2 3 (-2) +0 +2 = 8 = 2 3 3 3 3 (-2) +0 +2 = 0 = 0 Found by inspecting solutions of type -x, 0, x.
Let L be the length
of the stick. Let O be the center of the circle and let P be the point
where one endpoint of the stick lies on the circle. If Q is chosen on the
circle so that PQ=L and a is the measure of angle OPQ, then 2a/2pi is the
probability. Note that OP=OQ=R, so by the law of cosines R^2= L^2+R^2-2RLcos(a)
==> cos(a)=L/2R. This allows us to solve for a.
For L=R, we have cos(a)=1/2 ==> a=pi/3 ==> prob=1/3.
For L=2R, we have cos(a)=1 ==> a=0 ==> prob=0.
For L=R/2 we have cos(a)=1/4 leading to prob= invcos(1/4)/pi.
(This doesn't have a simple inverse.)
part a) 1/3
part b) 2*acos(1/4)/360=0.4196
part c) 0
answer= arc of intersection of circle with rad=sticklength/ 2*pi*R
Ryan says, Put one end of the stick at point A at the southern tip of the circle. Lay the stick in a roughly northeasterly direction to intersect the circle at point B. From A draw diameter AC directly north. Call O the center of the circle.
Angle BAC is the maximum angle that the stick can make clockwise from north and still fall entirely within the circle. Draw line BO, forming equilateral triangle ABO. The angle CAB is 60 degrees = 1/3 of the 180 degrees in the north-south direction; i.e., the probability is 1/3 that the stick will be inside the circle.
*****
(b) How would your answer change if the thin stick were
of length R/2 or 2R? How did you solve this?
*****
Refer to the points and layout described above in my
reply to part (a).
A stick with length of 2R will fit from point A only if it lies directly north, a 0 probability. (Some may ask how something that is possible can have a 0 probability, but lets not quibble over that.)
For a length of R/2. let R=2, stick length=1, and the
diameter AC=4. Again, lay the stick out in a northeasterly direction to
point B. Draw line CB, forming the right triangle ABC. (Angle ABC is 90
degrees, since it intercepts a/2 if the circle.)
Line BC is sqrt(4^2-1^2) = sqrt(15). Using BC as the base, the area of the triangle is sqrt(15)/2.
Draw line BD directly west, intersecting the diameter AC at point D. Using AC as the base for calculating the area, yields the altitude BD = sqrt(15)/4 =.9682... The stick (AB) of length =1 is the hypotenuse of right triangle ABD. This gives angle DAB the arcsin(BD) = 1.318 radians or about 75.52 degrees.
Dividing the radian angle by pi radians (180 degrees) yields .4196 as the probability of the stick being entirely within the circle.
"Let the lines extend outside the circle." For example: Circle centred at (0,0), radius 1. Draw lines:
(a) (-1,0) to (1,0) (b) (0,0) to (0,2) (c) (0,0) to (0,-2) Or: (a) (-1,0) to (1,0) (b) (0,-1) to (0,1) (c) (17,6) to (19,6)In either case, the lines, all 2 units long, divide the circle into four congruent areas.
Darrell Plank: If you're going to allow lines to be drawn partially outside the circle, why not entirely outside the circle? Two lines the diameter of the circle divide it into four pieces, the third line drawn entirely outside the circle.
Darrell Plank: I'm not sure the problem is well defined. What does a "random line of length s in a circle" mean? Pick a random spot for it's center and then a uniform distribution among all the angles which leave the stick inside the circle? Or tack down one end at a uniformly distributed random point and pick the other end based on a uniform distribution of legal angles from the tacked down point? Or pick one point at random inside and the other point at random a distance s from the original - discard if the second point lies outside the circle. Or uniformly pick from the region of four dimensional space which represents two legal points. My guess is that each of these definitions would end up with a different value.
No solution known, yet. But we can
take a guess. Obviously, the smaller the region of the land on the globe,
the lower the chances of you being able to hit the land with a random throw.
We can very roughly approximate the solution by comparing the area of Kansas
on the globe (213,109 sq km or 82,282 sq mi) to the area of Earth. The
area of the Earth is 197 million square miles This means that the ratio
of the area of Kansas to the area of the Earth is 82,282/197,000,000= 0.00041767512690355329
or .04%. Because the Earth's area is about 2394 times the area of Kansas,
you have a 1 out of 2394 chance of hitting Kansas on your first try --
if you were to throw a dart at the globe. Not very good odds! Your odds
are slightly increased because your are not throwing a dart but rather
an object shaped like Kansas. Unlike a dart, the midpoint of her tossed
Kansas need not fall on Kansas. You might approximate the answer by modeling
Kansas as circle of radius r. This means that if the tossed Kansas's center
within r miles of the edge of the Kansas on the globe, this counts as a
hit. Can you determine how much this increases your odds of hitting Kansas?
A triangle can be formed
only if the breaks are on opposite sides of the midpoint of the bone. For
this, the probability is 1/2. Also, the breaks must be less than 1/2 the
bone's distance apart. For this, the probability is also 1/2. Therefore
my answer is 1/4.
Blackstone writes that we solve the following statement
of the problem. We choose a point (x,y) uniformly at random from the unit
square. From this point, we construct the lengths (x, y-x, 1-y) (if x
Consider the case 0 Gillogly says, I assume the bone we were handed is a red
herring, since the next sentence appears to refer only to bone fragments
in sets. I further assume that we're interested in all shatter experiments,
not just the ones that resulted in triangles.
Since it's asking for the most likely ratio, that appears
to refer to the mode. The flip answer is that any ratio is as likely as
any other, since they are broken at random, and we assume that to be continuous:
any particular ratio has probability 0 of being selected.
If we're looking for the mean ratio over a large number
of breaks, that appears to be in the neighborhood of 3.597. And this should
be "the neighborhood of 2.80".
Another way of looking at this would be to consider ranges
of ratios, to see if these "mode buckets" peak somewhere other than at
the mean.
Interestingly (to me, anyway), this does indeed show a
mode bucket that's well below the mean: with buckets 0.1 wide, it appears
to peak in the 1.9-2.0 range. The mean ratio is higher because of a very
long tail of very high ratios. And this should be a mode bucket near 2.1-2.2.
I solved this by simulating the tricky bits.
Mayer says, The probability can be found analytically
as follows:
Let the total length be normalized to 1. Let the lengths
of the 3 pieces be x, y, and 1-(x+y).
In order to form a triangle no piece can be longer than
0.5, and furthermore y must be between 0.5-x and 0.5 for a given x.
Integration over all values of x and y forming a triangle
yields:
>(a) An alien takes a leg bone, N feet long, and shatters
the leg into three pieces at random. What is the probability that these
three pieces can be placed together to form a triangle? **** Ryan:Give
the bone a length of one unit. Mark the mid-point as .5. The breaks must
be on opposite sides of .5. Probability = 1/2.
Also, the break below .5 must be farther from 0 than the
higher break is from .5. Probability = 1/2.
Combined probability = 1/4.
***** QUESTION For the second part of this problem, the
alien hands you the longest piece of his most recent shatter experiment.
If you were a betting person, what is the most likely ratio of the longest
piece of bone to the shortest piece of bone in each shattered set? How
did you solve this?
Scientists have determined that bones contain a zillion
molecules per milligram. It is called Adams constant (A) after his proverbial
rib.
Fortunately, you are a pharmacist who is used to weighing
things exactly. When the alien hands you the longest piece, you are able
to determine its precise weight (W) in milligrams.
You are given no information about the other two pieces.
But regardless of the length of the second longest piece, there is always
a chance that the shortest piece contains exactly one molecule, making
it the most likely length of the shortest piece. This is true of no other
size. The most likely ratio is AW/1.
If you have no information about the longest piece, you
pick up an unbroken bone and determine its weight. Then you reason as follows:
If I make two random cuts in a rod, after the first cut,
there is always a chance the my second cut will result in the longest piece
being 1/2 the length of the rod. This is true of no other length, making
it the most likely outcome. Then proceed to determine the most likely ratio
as described above.
Darrell Plank: Just FYI - there's a kinda barely similar
problem solved in the Mathematica Journal V 7, Issue 2 where the question
is the area of a triangle formed by three random points in a square. He
goes through all sorts of machinations, most of them devoted to partitioning
up 6 dimensional space appropriately to arrive at the ultimately unsatisfying
answer of 11/144. It's interesting reading.
Blackston: Let p be the probability of hitting and P be
the probability of A surviving in the first scenario. With probability
p A will hit B and therefore survive. With probability (1-p)^2, both A
and B will miss their first shots leaving us in the same situation as at
the beginnining. This leads to the conclusion that
P = p + P(1-p)^2 ==>
It's interesting that as both ship's accuracy decreases
from 50% to 10%, ship A's survival decreases. Does this imply that if the
accuracy is very poor that ship A's odds of survival go to zero?
Meyer says, for a general probability p ship A can survive
if: It hits B right away - probability p It misses, B misses, and then
it hits - probability p*(1-p)^2 If A and B miss twice first, and then A
hits - probability p*(1-p)^4 etc. The general expression is p*(1-p)^(2*n)
The sum of the geometric series p*(1-p)^(2*n) is p/(1-(1-p)^2) (first term
divided by one minus the ratio), and this can be rewritten as 1/(2-p).
For p = 0.5 (50%) this is 2/3 (about 66.7%) For p = 0.1
(10%) this is 10/19 (about 52.6%)
In the Fibonacci sequence case let F(n) be the nth term
(F(1) = 1, F(2) = 1, F(3) = 2, etc.) For a general probability p ship A
can survive if: It hits B right away - probability p It misses, B misses,
and then it hits (2 chances) - probability (1-(1-p)^2)*(1-p)^2 If A and
B miss first (7 misses), and then A hits (5 chances) - probability (1-(1-p)^5)*(1-p)7
etc. The general expression is (1-(1-p)^F(2*n-1))*(1-p)^(F(2*n)-1) The
sum of the series can be done numerically.
For p = 0.5 (50%) this is about 69.5%
Another way to look at this: For any n, consider (n+1)!+2,
(n+1)!+3, ..., (n+1)!+n+1. For 2<=k<=n+1, k|(n+1)!+k, so this is
a sequence of n consecutive composite numbers. Let n=10000 to finish this
off.
10,001! + 2 through 10,001! + 10,001
Blackston says,we can explain the factorial problem in
the following way. We wish to find N such that N, N+1, ...., N+(n-1) are
all composite. We rewrite this as N+2, N+3, ... N+(n+1) (for a shifted
N). We know that if 2|N, then 2|N+2. Similarly if k|N, then k|N+k. The
simplest way to guarantee that all of these are composite is to ensure
that 2, 3, ..., n+1 are all factors of N. N=(n+1)! fits the bill, but isn't
the smallest.
In slightly different words, the easiest way to force
a number like N+k to be composite is to force k to be a factor of it. We
choose N so that all of the sums are composite. Becca: This is quite a
simple one, when you consider that it has been proven that for any integer
k you can find a consecutive string of k! integers which contains no primes.
No one has yet plotted this for rational numbers only.
a = (1+1/k)**k; b=(1+1/k)**(k+1)
for k = plus or minus, 1, 2, 3, .... but I'm not sure
what the plot looks like when examined with magnifying glass.
Here is how we arrive at a and b. If we let b=ra, we get
a**(ra)=(ra)**a. Next, a**r=ra, a**(r-1)=r, a= r**(1/(r-1)). Now, we said
from the start that are interested in rational numbers. Assuming r is rational,
a will be rational whenever 1/(r-1) is an integer, that is when r = 1+1/k.
Thus, we find a = (1+1/k)**k; b=(1+1/k)**(k+1) for k = plus or minus, 1,
2, 3, ....
Blackston says, I've seen problem 15 before, but not expressed
in the terms of rational solutions. It can be shown that if x is any real
> 1, then if a=x^{1/(x-1)} and b=a^x, then a^b=b^a. The reverse also holds.
If 1 a. 0880598016 (using the Unix bc calculator) This Legion
number has 1881 digits.
N! will contain factors for every integer ending in 0
or 5 up to N, and each of those will produce at least one extra 0 at the
end. Anything else with an extra power of 5 (e.g. 25) will produce another
0. This means 666! will have well over 100 0's.
Just for fun Gillogly written a program using another
arbitrary precision packaged called GMP (Gnu Multi-Precision) that produces
both the result of problem 17 and also calculates the last 10 digits It calculates the last 10 digits of 666^666, verifying
the bc result. It then strips off the 0's from the end of 666!, then raises
that number to the 666! power modulo 10,000,000,000 to get the last 10
digits of 666! ^ 666! before the 0's start. Results:
666^666 ends in 880598016.
666! ^ 666! ends in 1787109376 followed by 165 0's.
For part 2, suppose someone videotapes all 1000 shots
and reorders the tape clips so that the shots are shown in order, from
best to worst. Then the first and last shots are among the 1000 clips in
either of two orders (I) the first shot before the last shot, or (II) the
last shot before the first shot. Both cases being equally probable, one
in two hence is the probability that the last shot was further from the
center than the first shot.
With proper odds, I'd place a wager. My answer does not
depend on the shape of the target. The solution would be different if I
knew that another player alternates turns with Mr. Eck.
Jim Gillogly: The videotape editing is a nice thought
experiment construct. It doesn't help, though, if Dr. Eck is manipulating
his results. I'm not ready to place a wager at any odds. I have no reason
to trust Dr. Eck, and I would suspect that he has placed his first two
(or 999) shots far enough apart that he can put the last one inside or
outside them, whichever is needed to win his confederate's bet. (However,
we were told that Mr. Eck's skill level is constant.)
Ed Murphy. This incorrectly assumes that (I), (II) and
(III) are equally likely. If Dr. Eck fires two shots at a target, each
taken with equal accuracy, then it is equally likely for the first or the
second to be more accurate than the other. Doesn't matter how many shots
he or anyone else takes in between, nor the shape of the target.
> This incorrectly assumes that (I), (II) and (III) are
equally likely. Risto: Then please provide the actual probabilities. Or,
failing that, order the three events from most to least likely. Please
also explain reasoning.
> If Dr. Eck fires two shots at a target, each taken with
equal accuracy, then it is equally likely for the first or the second to
be more accurate than the other.
True, if I understood correctly (I think you mean any
two arbitrary shots, one of which you call 'first' and the other one 'second'
in the above paragraph).
Note, however, that the problem statement explicitly says
that the very first shot is better than the very next, if that is what
you mean by 'first' and 'second'.
> Doesn't matter how many shots he or anyone else takes
in between, nor the shape of the target.
False. Every shot that is worse than the first one gives
information about how hard it is to beat - and so does every shot that
is better than the first one.
So if he shoots 2001 times and 285 shots are better than
the first one, and 1715 shots are worse than the first, would you still
say that the 2002nd shot has a 1/2 chance of being better than the first
shot? (ObPuzzle: What is the actual probability of the 2002nd shot being
better than the very first one in the situation described above?)
>Note, however, that the problem statement explicitly
says that the very first shot is better than the very next, if that is
what you mean by 'first' and 'second'.
And in fact if you didn't have that information, (I),
(II), and (III) would still be equally likely, but you would also have
to account for three additional cases with the first and second shot in
the
(IV) second and first clip; (V) third and first clip;
(VI) third and second clip
In two of these cases, the third shot is ranked before
the first shot, so if you knew only that the first shot was _worse_ than
the second, the third shot has a 2/3 chance to be better than the first,
whereas if you don't know which of the first two shots was better the chance
becomes 3 out of 6 equal possibilities, i.e. the 1/2 you were looking for.
>So if he shoots 2001 times and 285 shots are better than
the first one, >and 1715 shots are worse than the first, would you still
say that the >2002nd shot has a 1/2 chance of being better than the first
shot? > >(ObPuzzle: What is the actual probability of the 2002nd shot being
>better than the very first one in the situation described above?)
Continue to assume that all the shots are independent
and identically distributed ("his skill level is the same"). Also continue
to assume that there is zero probability that two shots are the exact same
distance from the target.
Suppose Dr. Eck fires a total of N shots at the target,
N > 2. Then we can enumerate N(N - 1) cases, each one specifying the ranks
(in the list of shots ordered from best to worst) of just the first and
last shots: for each of the N places in the ranking in which the first
shot may fall, there are N - 1 remaining places where the last shot may
fall. By symmetry, each of these cases is equally likely.
Now suppose that of the N - 2 shots between the first
and the last, M of them are better than the first, and N - M - 2 worse
than the first. This eliminates some of the cases we already enumerated;
the cases it leaves are as follows:
(a) First shot has rank M + 1, last shot has one of the
N - M - 1 ranks worse than M + 1. (I.e., there are N - M - 1 subcases.)
(b) First shot has rank M + 2, last shot has one of the
M + 1 ranks better than M + 2. (I.e., there are M + 1 subcases.)
There are N equally likely subcases altogether, so the
probability of case (b) is (M + 1)/N, and that's the probability that the
last shot is better than the first.
For N = 2002 and M = 285, the probability that the last
shot is better than the first is 286/2002 = 1/7.
Another, simpler way of looking at it: If you first sort
the first N - 1 shots according to how close they are to the target, there
are N different places where the Nth shot might fit into the final ordering
(either before all the others, after all the others, or between two of
the others). All those possibilities are equally likely, and M + 1 of them
make the last shot better than the first, so the chance is (M + 1)/N.
Al Zimmerman: The palest of the greenest aliens in each
row will be greener (well, perhaps not, but certainly no paler) than the
greenest of the palest aliens in each column.
For simplicity, call the palest of the green POG, and
the greenest of the pale GOP. (Curiously, these do in fact happen to be
common alien names.) Now look at the alien where POG's row crosses GOP's
column. Clearly this alien is at least as green as GOP but no greener than
POG. QED (which, disappointingly, isnot an alien name at all).
One of the easiest ways to attack this problem is to run
several experiments to convince yourself of the answer. For example, consider
a 4x5 rectangle of randomly placed greenness values. The higher the number,
the more green the alien. You'll seethat the palest of the greenest aliens
is always correct. Try it for the following random array of green values:
max-over-Y (min-over-X (F(x,y)) <= min-over-X (max-over-Y
(F(x, y)). Provable by an argument that requires very little mathematical
depth, as follows:
We know that, for any general x' belonging to X, and y'
belonging to Y: a) min-over-X ( F(x, y'))<= F(x', y') <---- note
that in the LHS, x would be that x which minimizes F(x,y'), y fixed at
y'.
Therefore for any x', y' : min-over-X ( F(x, y')) <=
max-over-Y ( F(x', y)) This holds for any x' and y'. So In particular it
holds true for that y' which maximizes, min-over-X (F(x, y')) Therefore,
max-over-Y (min-over-X (F(x, y)) <= max-over-Y (F(x',
y)) This holds true for any x'.
Palest in each column, say column_i: is Min-over-X F(x,
y_i) Greenest of (Palest in each column), over all columns, is: Max-over-Y
(min-over-X (F(x,y))
Similarly:
By our implication that we proved:
The result is true, for continuous sets X and Y. In the
rectangular array, X and Y are discrete sets.
Other new formulas... Well, you want something that will
be very close to the square of a rational number with a denominator of
9, 99 or 999, or a factor thereof. e.g, let's try f(n) = 100 f(n-1) + 36
n - 128, f(0)=1, which results in f(n) = 9/121*100¬n + (112 - 44 n)/121,
and say
sqrt(f(30)) = 272727272727272727272727272727.2727272727272727272727272727
08969696969696969696969696969696969696969696969696969696969 08280134680134680134680134680134680134680134680134680134676...
Can anyone compute more digits of this number?
We may compare this to the Great Pyramid of Egypt:
This means that the number of bricks to fill the Great
Pyramid = 1.58E11/64 = 2.47E9
Thus, 6.39E9/2.47E9 = 2.5 approx. So, the bricks used
to build this highway could be used to construct 2.5 solid replicas of
the Great Pyramid. I assumed no mortar between the bricks since the builders
of the GP didn't use any either.
Here is a problem you might enjoy which I once included
on a quiz at a technical college where I used to teach: Calculate the change
in the length of railway track from NYC to LA over for a temperature change
of - 20F to 110F. (even though - 20F is not especially realistic for LA,
and ignoring the presence of expansion joints)
delta L = a X L X delta T a = coefficient of themal expansion
for gray cast iron
= 6.8E-6/F X 2800 miles X 130F
The students were impressed with the answer.
Richard Heathfield: Because you did not specify which
"America" I will assume South America and take a wild guess that there's
at least one East-West line exactly 1000 miles long.
Okay, how wide is our road? How about 11'6"? Is that wide
enough? (I think it was about that wide for Dorothy, and if it's good enough
for her...)
So we have 1000 * 1760 * 3 * 11.5 square feet of road
to cover. I'm assuming it's 1 brick deep. After all, these are magic bricks,
right? So no need for all that tedious stuff that usually goes underneath
roads...
The "standard brick"'s longest two dimensions are 8.625"
x 4.125". Conveniently, and without any fiddling at all, this means that
the road will be exactly 16 bricks wide. (If you want the traditional staggered
effect, you need to chop a brick in half every other line, but it doesn't
affect the count.) So we need 16 * length of road in inches / 4.125, which
is
16 * 1000 * 1760 * 3 * 12 / 4.125
= 245,760,000 bricks. Call it 300 million, to be on the
safe side (might have to build viaducts, and bridges, and stuff like that,
as we go).
Given the solution to problem 1, I'd be surprised if
an average ratio existed, but I don't really feel like evaluating an icky
integral...
0.5 0.5 0.5
I1 = I I dy dx = I x dx = 1/8
x=0 y=0.5-x x=0
Integration over all values of x and y yields:
1 1-x 1
I2 = I I dy dx = I (1-x) dx = 1/2
x=0 y=0 x=0
The probability of forming a triangle is p = I1/I2 = 1/4.
13. The Mystery of the Phasers
I look at the problem
this way. The chance of A hitting B with his first shot is 0.5. Next we
give B a chance. He may kill A. We must add .5*.5*.5. We gradually develop
a series: .5 + .5*.5*.5 + .5*.5*.5*.5*.5+... = .5*(1 +1/4 + 1/42
+ 1 /43+...) = .5*(4/3)=2/3. (Can anyone tell where the 4/3
comes from?)
P = p/(1-(1-p)^2)
For p=1/2, P=2/3. For p=1/10, P=100/190=10/19.
For p = 0.1 (10%) this is about 54.4%
14. Consecutive Nonprime Numbers
The answer is 10001!+2,10001!+3,...10001!+10001. The sequence
is nonprime (i.e. composite) since we know that n!+A is divisible by A
when A>1 and (A < n+1)
15. A Pretty Plot?
Mayer says the plot looks somewhat like a hyperbola, passing
through (2, 4), (e, e), and (4, 2). However, note that we are asking for
only rational solutions. What would such a plot (with rational solutions)
look like?
| *
| *
| *
| *(2, 4)
| *
| *(e, e)
| *(4, 2)
|_________________*
With regard to problem 15, I believe there is a way to derive
an expression for all rational solutions that looks like
16. A Bizarre Infinite Series
No solution known, yet.
17. Legion's Number
Legion Number of the Second Kind: The last 10 digits of 666!
are 0 since 5^10 and 2^10 both divide 666!. This means that the last 10
digits of (666!)^(666!) are also 0.
b. 0000000000 (N! ends in all 0's for sufficiently large
N)
Gillogly says, for straightforward medium-sized calculations
with arbitrary precision,
the Unix program bc is very convenient. It allows
the ordinary calculator functions, variables for assignments, some math
functions, and even looping, so that full programs can be created.
/* Pickover's Problem 17: last 10 digits of 666^666 and 666! ^ 666!
*
* Jim Gillogly, Dec 2000
*/
#include
Last 10 digits of 666^666: 880598016
666! =3D
1010632056840781493390822708129876451757582398324145411340420807=
35741380210369702298920280680149101204098980220355752703933970405713
07
293=
02834542423840165856428740661530297972410682828699397176884342513509
49
378=
74807749034933892552628783417618832618994264849446571616931313803111
17
619=
57305152642332038964180541081606760789306748325981681536460982866866
27
481=
10385603657973284604842078094141556427708745345100598829488472505949
07
196=
77272709119650608852092943406655064802264260833579015030977811408324
97
013=
73807911277761571911620331754219999948922714475266708579675248268885
04
612=
63732284539176142365823973696764537603278769322286708855475069835681
64
371=
08461405697693300657754144130835010436595722994544465172428240021405
55
140=
46429629100190143841467573055296491456926973403850076414055114364283
61
286=
13304734147348086095123859660926788460671181469216252213374650499557
83
174=
19505948271472256998964140886942512610451966725674955322288267193816
06
116=
97400311264211156133257350321296072971178199390387741639438171846476
55
275=
75014252129040283236963922624344456975024058167368431809068544577258
47
298=
39794378180726482136086500987493697610569612037912653636656646968022
45
199=
96204004154443821032721047698220334845859609307929656956126740947391
41
241=
32102055811493736199668788534872321705360511305248710796441479213354
54
258=
35760765962502134546679688379960232731630690947004294671066639254195
81
193=
13633986054565867362395523193239940480940410876723200000000000000000
00
000=
00000000000000000000000000000000000000000000000000000000000000000000
00
000=
00000000000000000000000000000000000000000000000000000000000000000000
00
We stripped 165 zeroes from the end of 666!
Last n digits of (666!)^(666!) (not counting 0's): 1787109376
Darrell Plank: 666¬666 = 2.7154175928871285582608746e1880
using logs and mathematica so the first 10 digits are 2715417592. Using
base 10, log(666!)=1593.00459306976630675482696146. If we call this L then
log(666!¬666!) = 666! * L= (10¬L) * L= 1.01063205684078149339082271E1593
* 1593.00459306976630675482696146 = 1.60994150845091005477479540E1596 =
M * 10¬1596. Taking 10 to this power gives (10¬M) * (10¬10¬1596).
Obviously the right factor is a large but integral power of 10. The left
gives 10¬M = 40.732541480224810426094063 so the first 10 digits of
666!¬666! should be 4073254148. A little more interesting than the
last 10 digits.
18. The Tombs, Part 1
If we assume that the people randomly
diffuse like particles in a gas, the number of people in each tomb is proportional
to the area of the tomb. Therefore, most people will be in the last tomb
J.
19. The Tombs, Part 2
We'd approach this by thinking about human psychology. For
example, if people thought that there was chance of escape, retrieval,
or visits, a higher density might remain in tomb A, where the people were
added originally. Using your creative brains, I bet you could come up with
some fun and interesting additional answers.
20. Phasers on Targets
Risto Lankinen: For part 1, suppose someone videotapes all
three shots and reorders the tape clips so that the shots are shown in
order, from best to worst. Then the first and second shot can be in (I)
first and second clip, (II) first and third clip, or (III) second and third
clip. Only in one case is the third shot better than the first; two in
three hence is the probability that the last shot was further from the
center than the first shot.
David A. Karr:
21. Greenness
Let g denote palest
of the greenest aliens.
Let G denote greenest of the palest aliens.
-------------------------------
| |
| |
| G |
| |
| |
| g X |
| |
| |
| |
| |
-------------------------------
So g >= X >= G. This seems to imply that the palest of the
greenest aliens is the solution. How can you be sure? How would you convince
your friends of this?
1 11 3 17
4 2 16 18
20 7 15 12
8 19 6 13
10 9 14 5
Dharmashankar Subramanian:
This greenness question is interestingly, a question
about the statement of weak duality of nonlinear programming. For the rectangular
array:
Let us index the rows as x (row_k is x_k) belonging to
set X.
Let us index the columns, as y (column_i is y_i, say)
belonging to set Y, and
Let F (x, y) be the function denoting "greenness". In
the rectangular array, every (i,k) pair (where x_k belongs to X, where
y_i belongs to Y), will have a value given by F(x_k, y_i) that denotes
the "greenness" of the alien-entry at the (i, k)th position in the array.
Cliff's question, in other words, is: Is max(over Y) (min (over X) F(x,
y)) <= min(over X) (max (over Y) F(x,y)), Or Otherwise ? Weak Duality's
implication is:
b) F(x',y') < = max-over-Y (F(x', y)) <----- similarly
note that in the RHS, y would be that y which maximizes F(x', y), x fixed
at x'.
So In particular, it holds true for that x', which minimizes,
max-over-Y (F(x', y) Therefore:
max-over-Y (min-over-X (F(x,y)) <= min-over-X (max-over-Y
(F(x, y)).
Greenest in each row, say, row_k: max-over-Y (F(x_k,
y)
Palest of (Greenest in each row), over all rows, is:
min-over-X (max-over-Y (F(x, y)).
Greenest of (Palest in each column), over all columns
<= Palest of (Greenest in each row), over all rows
22. Zebra Irrationals
Robert Israel (Department of Mathematics,
University of British Columbia, Vancouver, BC, Canada): The point being,
with previous work, that f(n) = 10¬(n+1)/81 - (9n+10)/81 so sqrt(f(n))
is very close to 10¬((n+1)/2)/9.
Why do you want a number that will be very close to the
square of a rational number with a denominator of 9, 99, or 999?
23. How Many Bricks?
Dennis Gordon: To solve this problem,
we first consider bricks of dimensions 8" X 2" X 4" (common brick size
according to the Bricklayer's Union whom I called on the phone). Next consider
highway lanes of 12' (from Principles of Highway Engineering and Traffic
Analysis, 2nd Ed. by Fred Mannering and Walter Kilareski, 1998 - I phoned
the library for this one. The Reference Librarian told me that the book
says 12' is the ideal width, but that width varies according to the terrain.
Although a bit wide for Dorothy's yellow-brick road, let's consider a 4
lane highway and 2800 miles from NYC to LA. So, this road will have (2800
X 5280 X 12)X (12 X 12 X 4) = 1.02E11 square inches of area. I left out
the units to avoid being tedious. Or, will require 1.02E11/16 = 6.39E9
bricks to cover it (8" X 2" side up)
756' sides (square base);
481 ft tall originally;
Volume = A* h = 756 X 756 X 481/3 = 9.16E7 cubic feet
= 1.58E11 cubic inches.
= 2.5miles approx.
Return
to Cliff Pickover's home page which includes computer art, educational
puzzles, fractals, virtual caverns, JAVA/VRML, alien creatures, black hole
artwork, and animations. Click
here
for a complete list of over 20 Cliff Pickover books.